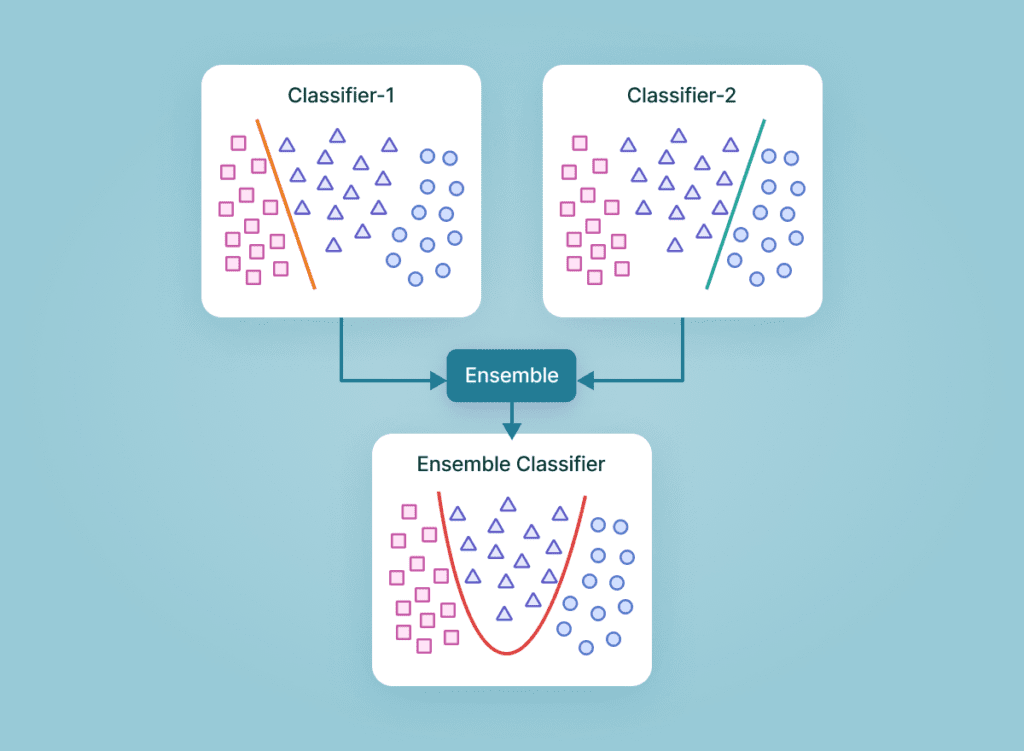
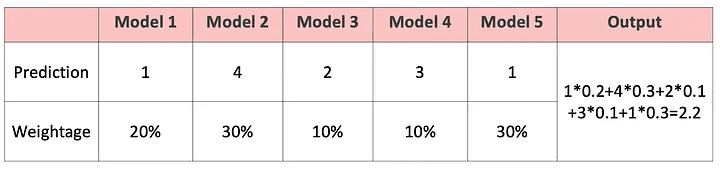
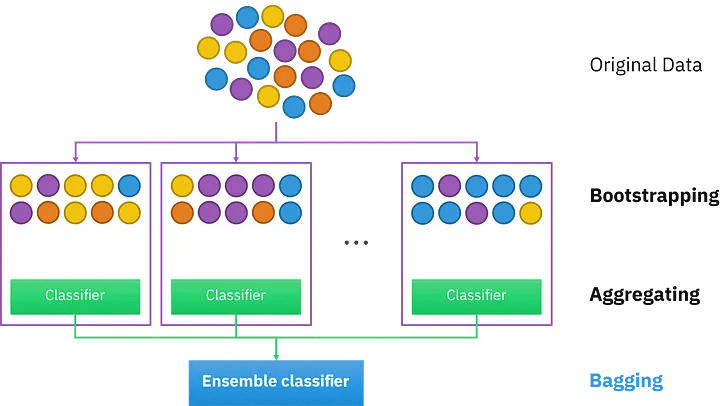
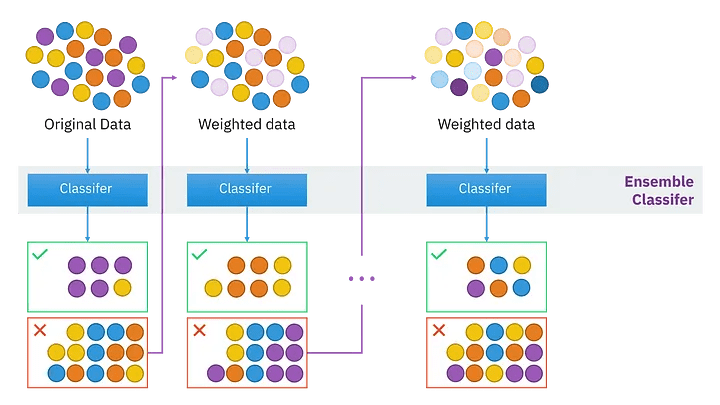
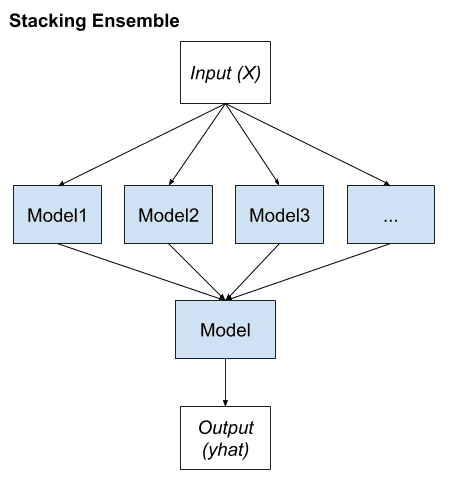
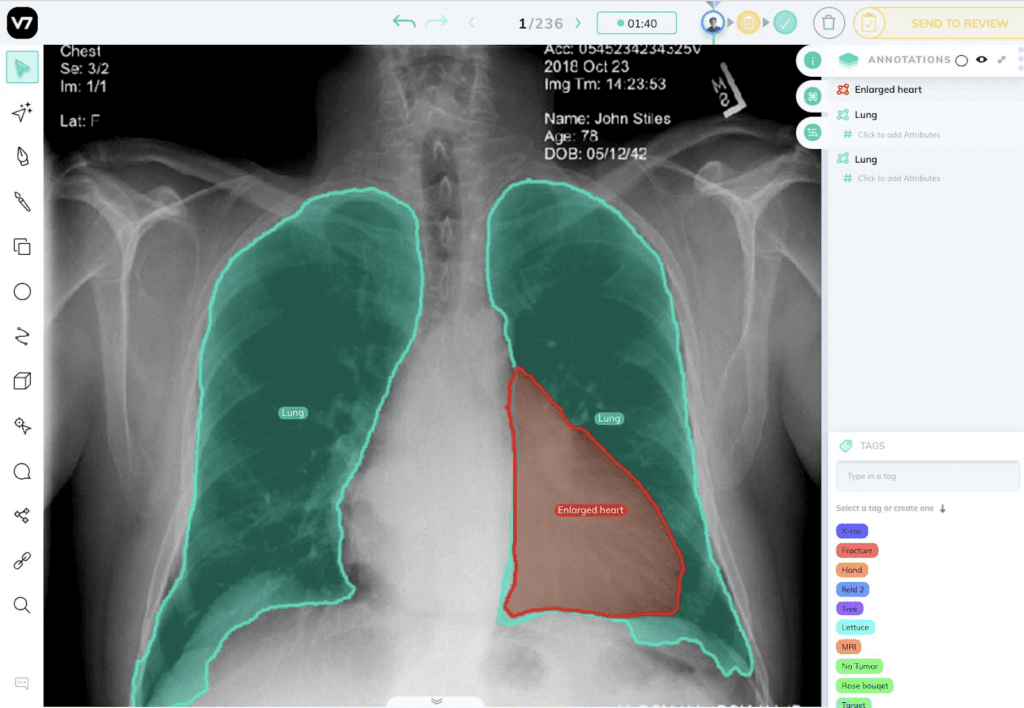
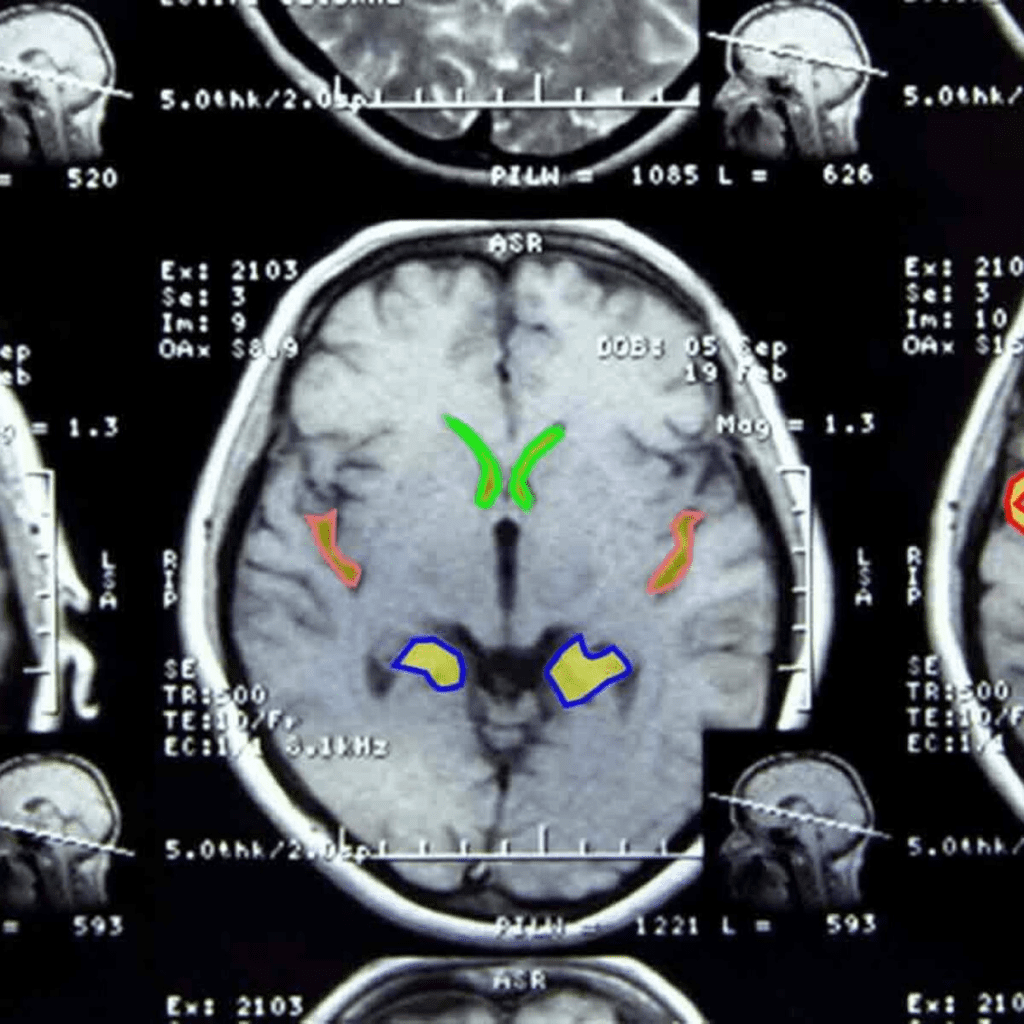
6月 27, 2023 アンサンブル学習とは?概要やアンサンブル学習の手法を紹介 アンサンブル モデリングは、最も焦点を絞った結果に関して、モデルのパフォーマンスを改善するための頼りになるツールです。様々な仕掛かりモデルの上に、アンサンブル学習を繰り返し、継続的に適用することに意義があります。アンサンブル・モデルは、Netflix Prize、Kaggleなどの機械学習コンテストで何度も利用されており、そのような実践から多くの恩恵を受けています。本記事ではアンサンブル学習の基本的な概念をご紹介するため、この分野の初心者で、アンサンブルの詳細に熟達したい方や、または分散とバイアスの豊富な知識をリフレッシュしたい方におすすめです。 アンサンブル学習とは? 機械学習としても知られているアンサンブル学習は、複数の予測モデルを組み合わせて予測性能を得る一般的なメタアプローチです。簡単に言えば、複数の情報源に基づいて情報に基づいた意思決定を行う行為です。例: アンサンブル学習分類は、メンバーの決定境界の混合です。アンサンブル学習回帰は、メンバーの超平面の混合です。この方法は、複数の学習モードとリソースから得られた洞察を組み合わせているため、アンサンブル学習の産物は、最も改善された適切な精度で到達する一般的な結論です。アンサンブルのメンバーによって促進された予測は、統計を使って融合することができるため、アンサンブルフレームワークは、統計的に多様な寄与モデルで最も成功します。 アンサンブル学習は機械学習です。 アンサンブル学習の仕組み アンサンブル学習は、各メンバーが持つマッピング機能の知識を組み合わせることで、予測結果の精度を高める手法です。アンサンブル学習のアプローチには、異なる結果の誤差に対する異なる寄与モデル、および、それぞれの異なるモデルの優れた点を操作しようとする予測の組み合わせ、という2つの重要な要素が必要です。 アンサンブル学習のメリット: なぜ使う必要があるのか? 下記では、アンサンブル学習の実用性と有用性を示すいくつかのシナリオを紹介します。これは、将来的にアンサンブル学習を試みるよう説得することを保証するものです。 1.単一の「最適」なモデルで決定できない データセットの中のある部分的な分布に対して、異なるモデルが他の部分よりも良い性能を示すという状況はよくあることです。例えば:あるモデルは犬と猫を区別するのは得意でも、犬と狼を区別するのは苦手かもしれません。同様に、あるモデルは文字のクラスではうまく処理できても、以前の「猫」のクラスでは不正確な予測を行うかもしれません。解決策:これら2つのモデルのアンサンブルは、3つのデータクラス間の最も識別性の高い決定境界を合成し、提案する可能性があります。要点: アンサンブルは、1つの究極の最適解に結合する能力に関して、単一のモデルで使用されるべきです。事実上、モデルの性能の期待値を平滑化するのです。 2.データの過不足 膨大なデータを扱う場合、分類タスクを異なる分類器に割り当て、予測時に集合させることで、1つの学習済みの分類器による大量のデータの分類よりも作業負荷の配分を良くすることが可能です。一方、バイオメディカル分野のように利用可能なデータセットが少ない場合、ブートストラップ・アンサンブル戦略を適用することで、同じサンプルを複数回出現させ、異なるモデルの後期学習を行うことができます。それを解決するのがバギング法です。要点: アンサンブル学習は、データの不足と過剰の両方の状況をうまく利用することができます。 3.信頼性推計 アンサンブルの枠組みの中核は、異なるモデルの予測に対する肯定的な信頼性に基づいて確立されます。上記の猫/犬の分類の例を続けると、4つのモデルには、等量の「猫」と「犬」サンプルを含む偏光予測があります。その結果、これら4つのモデルの間で最終的なコンセンサスを得ようとすると、アンサンブルの信頼度は低くなります。解決策: 研究者は、これらの個々の分類器の信頼度スコアを用いて、究極の最終スコアを生成することができます。要点:アンサンブルをより確実に成功させるためには、予測の信頼度が高い分類器をより重要視することがです。また、信頼度スコアに基づいたアンサンブルを構築することで、従来のような単純な多数決ではなく、より正確で信頼性の高い予測を行うことができます。 4.問題の複雑さ 決定境界は複雑であるため、単一の分類器で完全に処理し、適切な応答を生成することは不可能です。解決策: 複数の分類器を使用すること。要点:複数の線形分類器のアンサンブルは、任意の多項式決定境界を超越することができます。 アンサンブル分類器 5.情報融合 アンサンブル学習モデルを適用する最も一般的な理由は、分類性能を高めることです。この目的は、情報融合によって容易に達成することができます。つまり、異なるデータセット分布から学習され、同じクラスセットを獲得したモデルを予測期間中に集め、より頑健で強力な判断を生成することです。例えば、あるカテゴリーに特化した猫・犬の分類器は、プロの職人や機材のギアによって撮影された高品質で写真並みの画像を生成するために十分に訓練されているかもしれません。一方、別の分類器は、携帯電話の写真撮影者が撮影した低品質でぼやけた手ぶれ写真のコレクションを使って訓練されたものです。したがって、最も情報に富み、多角的で、偏りのないサンプル予測を行うには、両方の分類器を統合する必要があります。解決策: 情報融合により優れた精度を実現します。要点:単一の出力ではなく、複合的な出力を行うことで、より高い予測精度が得られることは間違いないでしょう。 アンサンブル学習の種類 アンサンブル学習法は、逐次アンサンブル法と並列アンサンブル法の2つに大別されます。 逐次アンサンブル法 このグループのベース学習器とモデルは、その名の通り順番に規則正しく生成されます。この場合、一般的な要点は、基本学習器の中間依存関係を操作して、予測精度を高めることを提案しています。 下記の2種類の例で考えてみましょう。ラベルの貼り間違いの例:その重みは調整され、変動し、改ざんされます。正しくラベル付けされた例:同じ重みは変更されません。そのため、新しい学習器を作るたびに重みが修正され、それに応じて精度が向上します。 並列アンサンブル法 一方、並列アンサンブル法では、相関依存性を持たずにベース学習器を並列に生成します。このようなアンサンブル学習の実行中、個々の学習器の予測を平均化スペクトルに配置することで一般的な誤差を抑制できるため、ベース学習器の独立性という事実上の状況が利用されます。 同種または異種 アンサンブルの学習方法を区別し分類するもう一つの方法は、同種か異種かということです。前者の概念は、単一種類の機械学習モデル/アルゴリズムを使用する状況を指します。アンサンブル学習の手法の大半は、同種カテゴリーに属します。一方、異種のアンサンブルは、多様な学習ベースから構成され、そのような様々な不一致により、学習者は可能な限り高い精度を持つことができます。アンサンブル学習のテクニックの様々な難易度を深く掘り下げる前に、ここでは、既存の一般的な手法を簡単に紹介します。下位レベルには、簡単なアンサンブルのテクニックがあります。平均化最大投票数加重平均より高度なレベルでは、下記のようなものがあります。。ブースティングバギングブレンディングスタッキング最後に、アンサンブル学習アルゴリズムには下記が含まれます。スタッキング投票エイダブーストランダムフォレストバギング クリティカル・アンサンブル学習手法 アンサンブル学習基本手法とは 初級レベルでは、アンサンブル学習の手法として、mod、平均、加重平均が挙げられます。具体的な内容は以下の通りです。 1.Mod: 統計用語で「最頻値」(Mode)とは、数値や値の集合の中で最も頻度の高い数値・値のことです。このアンサンブル手法では、機械学習の専門家がモデル番号のセットを操作して、各データポイントについて予測的な主張を行います。一方、異なる特異なモデルから構築された予測は、別々の個別の投票として受け入れられます。したがって、最も多くのモデルから構成される予測が、最終的な予測として順位付けされることになります。 3.最大投票数 この手法は、最も投票頻度の高い結果を出力するものであり、すべての予測モードを使用しているとみなすことができ、分類結果に適用されることが多いです。例えば、あなたはどのノートパソコン・ブランドを購入したらよいか、アンケートを取ったとしましょう。Mac、Dell、HP、Acer…などの回答がありますが、最終的にはAsus Vivobookが最も多くの票を獲得しています。投票数が多ければ多いほど、より信頼性の高いノートPCを購入することができます。このアンケート結果より、最終的には、結論としてAsusの購入に踏み切るという判断を下すことができます。 最大投票数 3.単純平均・加重平均 mean/averageアンサンブル法では、最終的な予測を導き出す過程にすべてのモデルを巻き込み、平均的な予測を考慮します。上記のイラストレーションや模範となる話に引き続き、Asusブランドを選択したあなたは、特定のモデルを追求する前に、さらに望ましい機能を決定する必要があります。ここでもまた、周りの人のおすすめを聞いたり、自分自身でネットで調べたりするわけです。単純平均:提示された機能のうち、最も多い数の単純平均を取るだけです。平均的な試算では、結論を出すためにあらゆる形式のモデリングを検討します。 単純平均 加重平均:あなたの購入目的は、デザイナーとしてのキャリアを向上させることと仮定します。したがって、ビジュアル面において特別なニーズを持たない、いつもの「非デザイナー」の友人からの推薦入力は、ビジュアル面において特別なニーズを持つ友人よりも、あまり考慮されないはずです。したがって、よりあなたのニーズに沿った意見に、より大きな配慮と重みを割り当てるべきです。同様に、これは加重平均を支配する中核概念であり、モデルに関連する重みは、モデルの関心度を意味するものである。 加重平均 先進のアンサンブル学習技術とは このパートでは、最もよく知られている3つの高度なアンサンブル学習技術(バギング、ブースティング、スタッキング)について説明します。その設計目的は、それぞれ特定のタイプの機械学習問題に対処することです。これら3つのアンサンブル学習法について熟知しておくことは、今後の予測モデル構築の計画立案に不可欠です。 バギングとは 「バギング」技術は、同じベース観測値から得られるモデルの予測値の分散を減らし、結果を変更するのに役立ちます。 アンサンブル学習:バギング ブースティングとは 「ブースティング」技術は、モデルのバイアスに対抗し、公平で偏りのない予測スタンスを維持するのに役立ちます。ブースティング・モデルの例としては、AdaBoost、XGBoost、Gradient Treeなどがあります。これらはすべて逐次アンサンブル方式に該当します。 アンサンブル学習:ブースティング スタッキングとは 最後に、一般的な予測精度を向上させるために「スタッキング」が行われます。 アンサンブル学習:スタッキング アンサンブル学習の応用 アンサンブル学習は、深層学習において広く実践されている手法であり、様々な問題に対処するために応用されています。最も注目すべき例は、複雑なパターン認識課題です。アンサンブル学習は、デジタル化された画像や映像から得られる高度な意味情報をコンピュータに学習させるのに役立ちます。例:物体検出(注目するオブジェクトや画像の分類には、バウンディングボックスを形成して囲むことが必要です。)その他にも、いくつかの実生活における応用が考えられます。 1.病気の検出 アンサンブル学習により、ますます単純でタイムリーな予後のための疾患の分類と位置特定がサポートされています。例:レントゲンやCTスキャンで発見される心臓血管の病気 AI胸部X線アノテーション解析 アルツハイマー病の検出: 画像研究(OASIS)データセット リモートセンシング 物理的な接触がないにもかかわらず、指定されたエリアの物理的な属性を監視することを「リモートセンシング」と呼びます。リモートセンシングは、さまざまなセンサーから取得されるデータの解像度が異なるため、データの分布に支障をきたす可能性があり、高度なタスクです。地滑り検出やシーン分類などの監視型センシングタスクを、アンサンブル学習の助けを借りて実現しました。 工事用地上の車両を注釈したカバーマップ 3.不正行為警告 デジタル不正を検知するためには、プロセスの自動化において分刻みの精度が標準となっており、重要かつ困難な作業となっています。アンサンブル学習は、クレジットカード詐欺や印象操作詐欺に対して、その有用性と鋭い検出力を実証しています。 クレジットカードの不正使用検知 4.音声感情認識 最後に、包括的ではあるが決定的ではない、アンサンブル学習もまた、音声感情認識、特に多言語シナリオにおいて適用されます。この技術は、1つの分類器に限定するのではなく、すべての分類器の効果のコンパイルを組み合わせることができるため、特定の言語コーパス(データベース)の精度を損なうことはありません。 音声感情認識 アンサンブル学習に関する重要なポイント アンサンブル学習は、機械学習の一般的な手法の一つであり、様々な学習モードと専門知識の情報資源(分類器)を組み合わせて予測することです。アンサンブル学習は、データ中心、アルゴリズム中心の解像度が必要である、データ不足、オーバーフロー、計算機資源の制約などの困難なシナリオを解決するための万能薬です。この組み合わせにより、単一モデルによる予測よりはるかに高いパフォーマンスを得ることができ、より優れた予測性能とモデルの頑健性を実現します。これは、アンサンブル学習がオーバーフィッティングの問題を解消し、異なるモデルのパワースーツをコンパイルして収集するためです。アンサンブル学習の導入をご検討中の企業様は、30年に及ぶ実績を持つCMC Japanにお任せください。ITの専門家2,200人以上が在籍するCMC Japanがお客様のプロジェクトをお手伝いいたします。 >> アンサンブル学習に関する無料相談はこちら この記事をシェアする